

Merhabalar arkadaşlar, hepimizin bildiği üzere son yıllarda veri toplama araçları ve veri tabanı teknolojilerindeki gelişmeler, bilgi depolarında çok miktarda bilginin depolanmasını ve çözümlenmesini gerektirmektedir. Birçok kaynaktan elde edilen veri yığınlarının içerisinde saklı bulunan bilgiyi bulma işlemine “veri madenciliği” denilmektedir. Bu işlemleri yapmak için açık kaynak kodlu ve ticari amaçlı birçok program kullanılmaktadır.
Açık kaynak kodlu programlar arasında WEKA, RapidMiner, KNIME ve R, ticari programlar arasında ise SPSS, SAS ve MATLAB sayılabilir.
Literatürde açık kaynak kodlu veri madenciliği programı olan WEKA ile yapılmış birçok çalışma zaten bulunmaktadır. Meme kanseri hücrelerinin teşhis ve tahmini, göğüs kanserinin teşhis ve tahmini, Parkinson hastalığının teşhis ve tahmini gibi çalışmalar vardır.
Bu yazıda bahsedeceğimiz örnek çalışmada ise amacımız, hastaların kan testi değerlerini tek tek okuyarak hastalık teşhisi yapan doktorların işini kolaylaştırmak amacıyla WEKA yazılımını kullanarak yapay zekaya anemi hastalığının teşhisini yaptırmak olacaktır. Anemi, klinik olarak hasta için geçerli referans aralığının altında bulunan kan, hemoglobin veya hematokrit değeri şeklinde tanımlanır.
WEKA’nın içinde hazır sunulan algoritmalardan k-NN (k-En yakın komşu) algoritmasını kullanarak örnek veri setimiz üzerinden çalışmamızı yapmadan önce WEKA nedir, buna biraz değinelim.
 Şekilde WEKA kullanıcı ara yüzü
Şekilde WEKA kullanıcı ara yüzü
WEKA; Yeni Zellanda’daki Waikato Üniversitesi tarafından geliştirilmiş, makine öğrenimi algoritmalarının bir arada barındıran, işlevsel bir grafik arabirimine sahip, açık kaynak kodlu bir veri madenciliği programıdır.
Örnek veri setimize değinecek olursak; 25 adet anonim anemi hastası ve 25 adet anonim anemi hastası olmayan bireylere ait hemogram test sonuçları bir excel tablosunda toplamda 29 input(girdi) ve anemi hastaları için “yes”, anemi hastası olmayanlar için “no” şeklinde 2 output(çıktı) olmak üzere toplanmış ve WEKA’da kullanılmak üzere .csv formatına dönüştürülmüştür. Örnek veriseti üzerinde kNN (k-En yakın komşu) algoritmamızı uygulayalım.
 Şekilde örnek veriseti
Şekilde örnek veriseti
kNN (k-Nearest Neighbours) Algoritması
k-En yakın komşu algoritması en basit ve en çok kullanılan sınıflandırma algoritmalarından biridir. kNN, non-parametric(parametrik olmayan), lazy(tembel) bir öğrenme algoritmasıdır. Lazy learning’in bir eğitim aşaması yoktur. Eğitim verilerini öğrenmez, bunun yerine eğitim veri kümesini ezberler. Bir sınıflandırma ya da tahmin yapmak istediğimizde, tüm veri setinde en yakın komşuları arar. Algoritmanın bakacağı eleman sayısı için bir k değeri belirlenir. Bir değer geldiğinde en yakın K kadar eleman alınarak gelen değer arasındaki uzaklık genelde öklid fonksiyonu kullanılarak hesaplanır. Uzaklık hesaplandıktan sonra sıralanır ve gelen değer uygun olan sınıfa atanır.
kNN (k-En yakın komşu) algoritması en yakın komşu sayısını belirleyen k değeri sırayla 3, 5, 7 ve 9 olarak uygulanmış ve yaklaşık %86 oranında başarıma ulaşılmıştır. Şekilde k=3 değeriyle elde edilen sonuçlar gösterilmektedir.
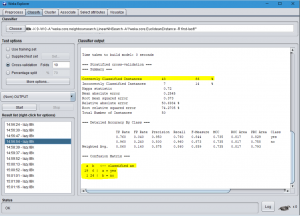
Daha sağlıklı sonuçlar elde etmek için veri kümelerimizdeki veri sayısının yeterince çok olması gerektiğini ve sonucu doğrudan etkileyebilecek bir takım değerler olup olmadığını kontrol etmemiz gerektiğini unutmayalım. kNN algoritmasının verdiği sonuçlara göre anemi hastalarının teşhisinde maksimum başarı oranı %86 olarak elde edilmiştir. Böylece her 100 hasta kaydından 86’sı yapay zeka tarafından doğru olarak teşhis edilebilmiştir.
KAYNAKLAR
- Coşkun, C., Baykal, A. 2011. Veri Madenciliğinde Sınıflandırma Algoritmalarının Bir Örnek Üzerinde Karşılaştırılması. Akademik Bilişim, Malatya.
- Danacı, M., Çelik, M., Akaya, A.E. 2010. Veri Madenciliği Yöntemleri Kullanılarak Meme Kanseri Hücrelerinin Tahmin ve Teşhisi. Akıllı sistemlerde Yenilikler ve Uygulamaları Sempozyumu (ASYU’2010), 21-24 Haziran, Kayseri, 9–12.
- Dener, M., Dörterler, M., Orman, A. 2009. Açık Kaynak Kodlu Veri Madenciliği Programları: Weka’da Örnek Uygulama. Akademik Bilişim, 11-13 Şubat, Şanlıurfa.
- Kudyba, S. 2004. Managing Data Mining. CyberTech Publishing, 146–163.G
- Machine Learning Classification kNN. (2018). Erişim adresi: https://medium.com/@ekrem.hatipoglu/machine-learning-classification-k-nn-k-en-yak%C4%B1n-kom%C5%9Fu-part-9-6f18cd6185d
- Özçift, A. 2011. Biyomedikal verilerin akıllı sistemler ile sınıflandırma başarımlarının analizi. Yayınlanmamış doktora tezi, Fırat Üniversitesi Fen Bilimleri Enstitüsü.
- William F. Kern, MD. Hemotology PDQ, 1.Baskı, İstanbul, İstanbul Medikal yayıncılık; 2005. 1-15.
- Witten I.H., Frank E., Hall MA. 2011. Data mining: practical machine learning tools and techniques. Elsevier, London.

